
只需 3 秒,从未听过你说话的 AI 就能完美模仿你的声音。 这就是微软人工智能的最新成果——VALL-E文本转语音模型,只需3秒的语音,就可以随意复制任何人的声音。
Microsoft VALL-E 会在说话 3 秒后模仿我们的声音
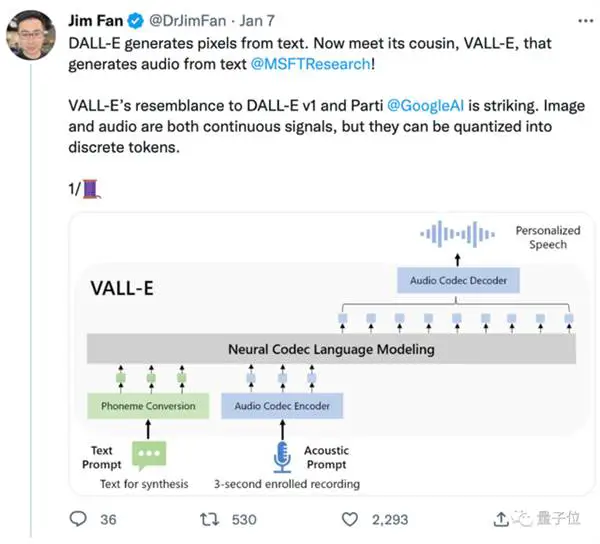
起源于DALL E,但专攻音频领域,文字转语音效果上线后火爆。
有用户表示,如果VALL·E和ChatGPT结合起来,效果会很惊人。 对于其他人来说,用人工智能进行视频通话的日子似乎已经不远了。 甚至有人开玩笑说,AI搞定了文画家,接下来就是配音演员了。

但VALL·E如何在3秒内模仿出一种“闻所未闻”的声音呢?
VALL-E 使用语言模型分析音频。 它基于人工智能“闻所未闻”的声音合成语音,即零样本学习。
传统的文本到语音解决方案基本上是一种预锻炼模式以及微调。 如果用于零样本场景,会导致生成语音的相似度和自然度较差。

基于此,VALL-E横空出世,提出了与传统人声模型不同的理念。
与传统的使用梅尔谱提取特征的模型相比,VALL-E直接将语音合成作为语言模型的任务,前者是连续的,后者是离散的。
特别是,传统的语音合成过程往往是“音素→梅尔谱图(mel-spectrogram)→波形”的路径。
而VALL-E将这个过程转化为“音素→离散音频编码→波形”:
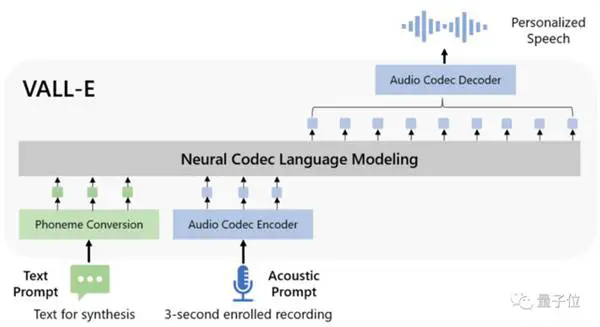
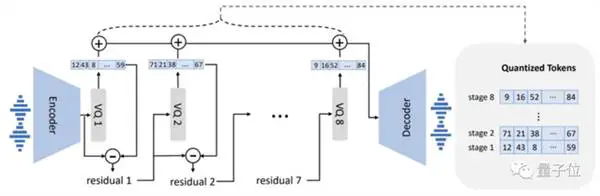
在车型设计上,VALL-E也与VQVAE类似。 将音频量化为一系列离散标记。 第一个量化器负责捕获说话者的音频内容和身份特征,而第二个量化器负责信号细化。 这听起来更自然:
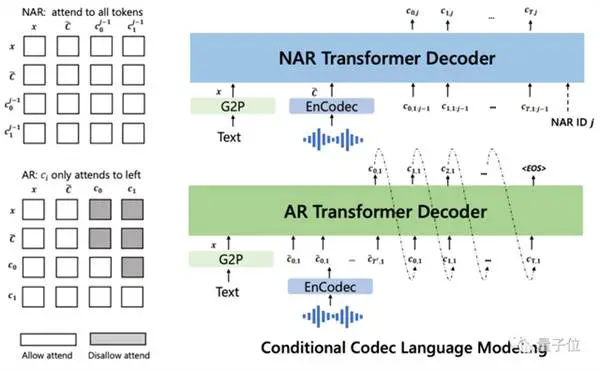
然后以文本和 3 秒音频提示为条件,它自回归输出离散音频编码:
但不仅如此,除了零样本语音合成,VALL-E还支持与GPT-3相结合的语音编辑和语音内容创作。
环境背景音也可以还原
从合成的人声效果来看,VALL-E能够还原的不仅仅是音箱的音色。
不仅现场模仿音高,还支持多种不同语速。 例如,这是 VALL-E 提供的两种不同的语速,当同一句话说两次时,但音调相似度仍然很高:
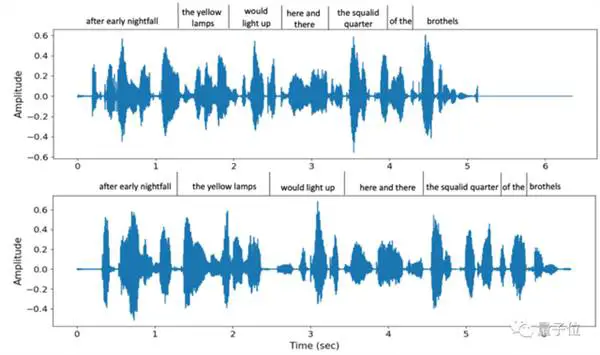
同时,对方的背景环境音也能准确还原。
此外,VALL-E 可以模仿说话者的各种情绪,包括愤怒、困倦、中性、喜悦和恶心等多种类型。
值得一提的是,用于VALL·E训练的数据集并不是特别大。
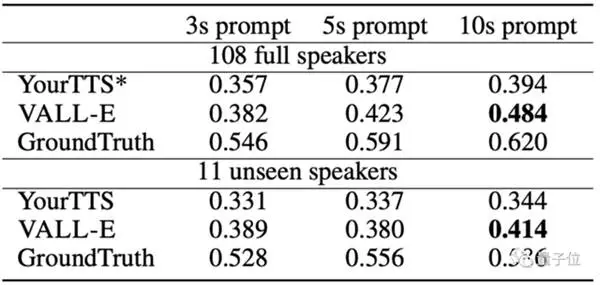
与 OpenAI 的 Whisper 需要 680.000 音频训练时间,仅使用 7.000 多个扬声器和 60.000 训练时间相比,VALL-E 在与 Model YourTTS 文本转语音的相似度方面超越了预训练文本转语音。
此外,YourTTS 在训练过程中提前听到了 97 个说话者中 108 个的声音,但在实际测试中仍然比不上 VALL-E。
至于可以应用的领域:
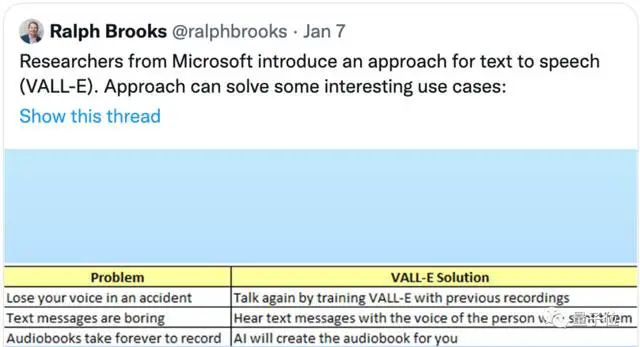
它不仅可以用来模仿你自己的声音,比如帮助残疾人完成与他人的对话,还可以在你不想说话的时候用它来代替你说话。 当然,它也可以用于有声读物的录制。
但是,VALL-E 尚未开源,您可能需要稍等片刻才能试用。







